Stream Processing Pipeline for Near-Real-Time Data Synchronisation to Support Personalisation Use Ca
Author : Covalense Digital | Published On : 16 Apr 2026
Introduction
When building a recommendation system, the quality of your data pipeline determines the quality of your recommendations. After evaluating Cassandra’s Batch Processing Platform (BPP), we decided to build our Universal Recommendation System’s data ingestion pipeline on Stream Processing Platform (SPP) with Apache Flink. Six months and millions of processed messages later, here is why it was the right decision and what we learned along the way.
Introduction to SPP and Apache Flink
Stream Processing Platform (SPP) is an enterprise streaming platform that provides event-driven processing, automatic deployment, monitoring, and native integration with Event Bus (Kafka). Apache Flink is the streaming engine powering SPP, providing exactly-once semantics, stateful processing, and horizontal scalability.
What Our Stream Processing Pipeline Delivers
For personalisation use cases, stale data means missed opportunities — a recommendation system is only as good as the data feeding it. Our pipeline addresses this directly by keeping recommendation data in near-real-time sync with source systems. This means newly published content is available for recommendation within seconds, incoming events are dynamically enriched before reaching the recommender, and delivery remains reliable at scale — so users always receive contextually relevant, up-to-date recommendations rather than yesterday’s data.
How SPP Helps Achieve the Above Use Cases
SPP provides event-driven streaming with sub-second latency (vs. batch delays), horizontal auto-scaling based on message volume, native Kafka integration and tooling, automatic checkpointing and state management, and SDK support with local development tools. These capabilities directly support our goals of near-real-time sync, scalability, and faster iteration for personalisation.
High-Level Stream Processing Pipeline Architecture
The architecture follows an event-driven pattern: Kafka Source → JSON Parsing → Dynamic Pipeline Orchestration → Recommender Output. Failed messages are managed via fail-fast and filtering (logged and dropped so healthy traffic continues).
Apache Flink serves as the streaming engine, providing exactly-once semantics, stateful processing, and horizontal scalability. SPP adds enterprise-grade features including automatic deployment, monitoring, and integration with the ecosystem.
High-Level Architecture Diagram
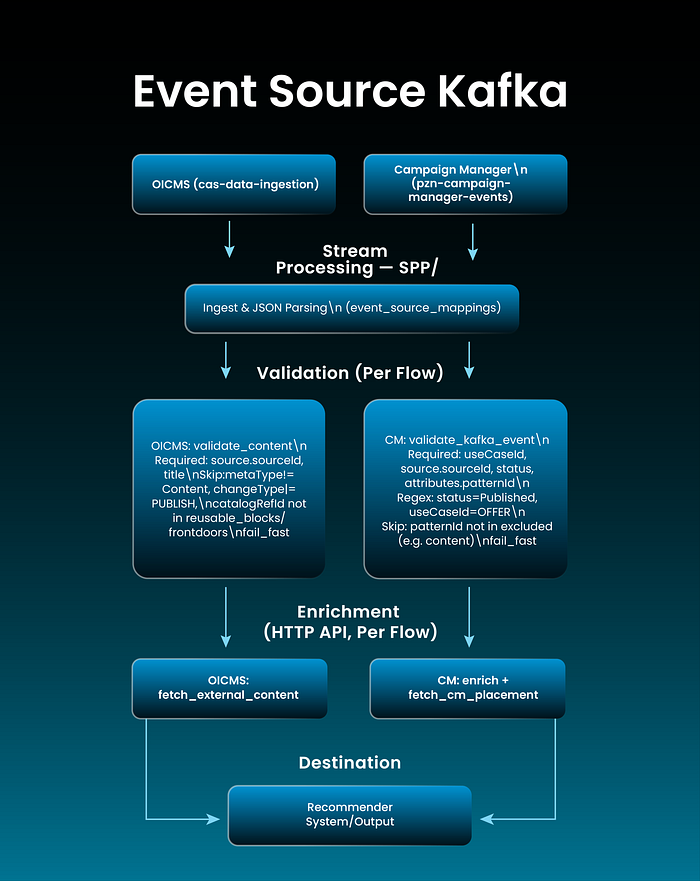
Explanation: Event Source: Two Kafka-backed flows: OICMS (content ingestion topic) and Campaign Manager (CM events topic).
Stream Processing — SPP on Apache Flink: shared ingest and JSON parsing; flow-specific validation (details in diagram for both OICMS and CM); flow-specific enrichment (OICMS: fetch external content; CM: recommender API + CM placement).
Destination: Both flows write to the Recommender System.

Why Real-Time Stream Processing Matters
Traditional batch processing systems collect data and deliver results hours or days later. For modern recommendation systems, this delay is unacceptable. Real-time processing enables immediate content availability, dynamic enrichment, and reliable delivery at scale. Understanding the right architecture for stream processing keeps engineering teams ahead of the scalability curve.
The Journey: From BPP to SPP
We started with a proof-of-concept using Cassandra’s Batch Processing Platform. While BPP is powerful for scheduled batch jobs, we quickly realised our recommendation system needed real-time, event-driven processing.
Advantages of SPP Over Batch Processing
- Real-Time vs. Batch: SPP provides event-driven streaming with sub-second latency, while BPP processes data in scheduled intervals with hours of delay.
- Scalability: SPP offers horizontal auto-scaling based on message volume, whereas BPP relies on vertical scaling with manual capacity planning.
- Integration: SPP provides native Event Bus (Kafka) integration and extensive tooling, reducing development time significantly.
- Operations: SPP handles automatic checkpointing and state management, while BPP requires manual job scheduling and failure recovery.
- Developer Experience: SPP includes SDK support, local development tools, and comprehensive documentation, making it much easier for teams to be productive.
- Reliability: We achieved 99.9% uptime over six months in production.
- Cost Optimisation: 40% reduction in operational costs through efficient auto-scaling and resource utilisation.
Our Architecture: Event-Driven Stream Processing
We designed a multi-stage processing pipeline built on Apache Flink that ingests content from Kafka, processes it through configurable stages, and delivers enriched data to the recommendation system in real time.
Key Architectural Decisions
Several deliberate design choices shaped the reliability, maintainability, and performance of our pipeline. Here is what made the most difference.
Configuration-Driven Pipeline Design
One of our most impactful decisions was making the entire pipeline configuration-driven. Instead of hardcoding processing logic, we externalised all processing steps, validation rules, and service endpoints into HOCON configuration files. This approach delivers significant benefits: zero-code deployments for pipeline modifications, environment-specific configurations (local, QAL, production), easy experimentation with different processing strategies, and deployment time reduced from hours to minutes.
Resilience and Error Handling Patterns
We designed the system expecting failures in distributed environments. Key resilience patterns include: Retry Mechanisms with exponential backoff for external API calls and configurable retry attempts per service; fail-fast and filtering so failed messages are logged and dropped without blocking healthy traffic; Circuit Breakers to prevent cascading failures when external services become unavailable; and Monitoring & Observability with structured logging and Splunk integration for real-time visibility into pipeline health, performance metrics, and error tracking.
Type-Safe Data Transformation
We integrated MapStruct for compile-time code generation of data mappings between DTOs and domain models. This approach catches mapping errors during compilation rather than at runtime, eliminating an entire class of production bugs and making refactoring safer.
Local Development Without Infrastructure
Running a full Flink cluster with Kafka locally is complex. We built a Local Producer tool that executes the complete pipeline locally without infrastructure dependencies. This reduced the developer feedback loop from hours to seconds, dramatically improving productivity and code quality.
Results in Production
Since deploying to production, our pipeline has delivered:
- Performance: Processing 10,000+ messages per second with p99 latency under 100ms end-to-end.
- Reliability: 99.9% uptime over six months in production.
- Operational Efficiency: Reduced deployment time from 2 hours to 15 minutes through configuration updates.
- Cost Optimisation: 40% reduction in operational costs through efficient auto-scaling and resource utilisation.
- Developer Velocity: Faster iteration cycles and reduced time-to-market for new features.
Lessons Learnt
- Validate Through POCs: Evaluating both BPP and SPP through proof-of-concepts saves months of potential rework. Hands-on experimentation enables confident architectural decisions.
- Configuration Over Code: Dynamic, configuration-driven systems are significantly easier to maintain, test, and evolve than hardcoded implementations.
- Design for Failure Early: Implementing comprehensive error handling patterns from day one prevented production incidents as the system scaled.
- Invest in Developer Tools: Building tools that improve the inner development loop has an outsized impact on team velocity and code quality.
- Type Safety Reduces Risk: Compile-time validation caught bugs that would have been costly production failures.
- Observability is Critical: Without comprehensive monitoring and structured logging, operating distributed systems at scale becomes impossible.
Conclusion
Choosing Stream Processing Platform over Batch Processing Platform gives us the low latency, scalability, and reliability needed for modern recommendation systems. Our configuration-driven architecture on Apache Flink with SPP’s enterprise features created a maintainable foundation for near-real-time data synchronisation to support personalisation use cases. Validating technology choices through POCs, prioritising configuration over code, and designing for failure and observability from the start were key to our success.
Want to build smarter pipelines with AI-first architecture? At Covalense Digital, we specialise in building intelligent, AI-first platforms that power real-time decisioning, personalised customer experiences, and scalable data pipelines — for telecoms, enterprises, and beyond. Whether you’re modernising a legacy BSS stack or engineering a next-generation data architecture, our expertise in AI/ML, iPaaS, and digital transformation can help you move faster and scale confidently.
Let’s connect at reachus@covalensedigital.com or fill in a quick contact form.
