handle anti-scraping mechanisms in modern websites
Author : anshul actowiz | Published On : 25 May 2026

Introduction
Ecommerce intelligence has become a critical component of modern business strategy as companies increasingly rely on real-time data for pricing optimization, competitor tracking, inventory monitoring, and market research. However, modern websites now implement sophisticated anti-scraping technologies that restrict automated access and disrupt large-scale data extraction workflows.
To maintain uninterrupted analytics operations, businesses must learn how to handle anti-scraping mechanisms in modern websites using scalable automation frameworks and intelligent extraction strategies. By leveraging an advanced Web Scraping API, organizations can automate ecommerce intelligence collection while reducing disruptions caused by anti-bot protections, CAPTCHA systems, browser fingerprinting, and request monitoring technologies.
Modern anti-scraping systems are designed to detect repetitive traffic behavior, unusual browsing patterns, excessive request frequencies, and non-human interactions. Without adaptive automation infrastructure, businesses often face incomplete datasets, unstable extraction pipelines, and unreliable analytics operations.
Between 2020 and 2026, the adoption of advanced anti-bot technologies has increased significantly as ecommerce platforms strengthen traffic security and protect digital assets. In response, enterprises are investing in resilient scraping architectures capable of scaling data collection without triggering detection systems.
Why Intelligent Bot Management Is Essential
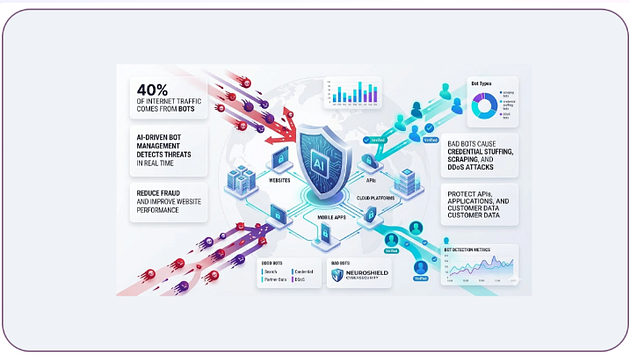
Modern anti-scraping systems continuously monitor incoming traffic behavior to identify automated activities and restrict suspicious requests. Businesses need adaptive bot-management infrastructures that can mimic natural browsing behavior while maintaining scalable data extraction capabilities.
Organizations increasingly adopt enterprise anti-bot handling strategies for web scraping projects to improve scraping stability and reduce operational interruptions. These systems combine traffic orchestration, behavioral analysis management, proxy rotation, and session control to support enterprise-grade ecommerce intelligence collection.
Key Components of Enterprise Anti-Bot Strategies
- Traffic pattern diversification
- Browser fingerprint management
- Intelligent proxy rotation
- Request throttling systems
- Session continuity handling
- Geographic request distribution
Enterprise Anti-Bot Adoption Trends (2020–2026)

Advanced anti-bot management frameworks help businesses maintain reliable extraction pipelines while scaling ecommerce intelligence operations efficiently.
Why CAPTCHA and JavaScript Challenges Require Advanced Automation

Websites increasingly use CAPTCHA systems and JavaScript-rendered content to distinguish human users from automated traffic. Traditional scraping systems often fail to process these protections effectively, leading to incomplete or blocked data collection.
Businesses increasingly focus on handle CAPTCHA and JavaScript challenges in scraping pipelines to improve extraction reliability across dynamic ecommerce websites. Advanced automation frameworks use browser rendering technologies, intelligent request orchestration, and adaptive challenge-handling systems to process modern web environments more efficiently.
Common Anti-Scraping Technologies
- CAPTCHA verification systems
- JavaScript-rendered interfaces
- Browser integrity checks
- Human interaction analysis
- Dynamic request validation
CAPTCHA Handling Growth Statistics
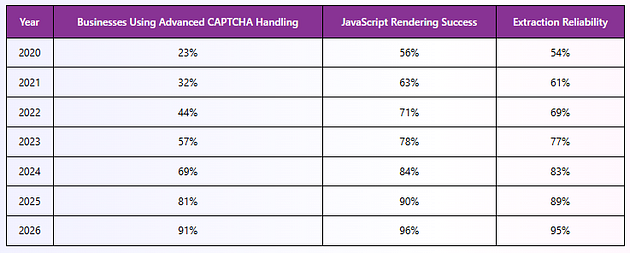
Advanced challenge-handling systems improve ecommerce intelligence continuity while reducing interruptions caused by modern anti-scraping protections.
How Modern Frameworks Improve Web Scraping Reliability
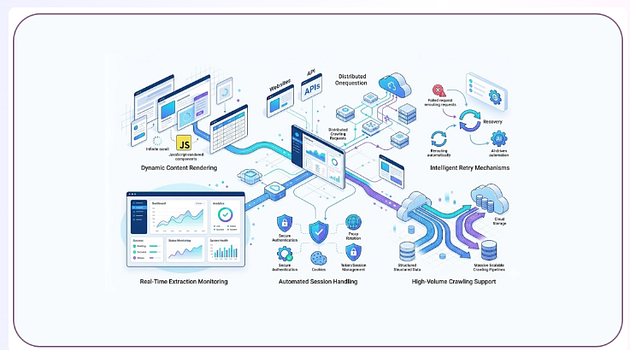
Modern websites feature highly dynamic layouts, asynchronous loading systems, API-driven content delivery, and advanced security layers. Businesses require robust technologies capable of handling these complexities efficiently.
Organizations increasingly implement tools and frameworks for reliable modern web scraping systems to support scalable ecommerce intelligence operations. Modern frameworks combine browser automation, distributed crawling, cloud orchestration, session management, and real-time monitoring to improve extraction reliability.
Features of Modern Web Scraping Frameworks
- Dynamic content rendering
- Distributed request orchestration
- Intelligent retry mechanisms
- Real-time extraction monitoring
- Automated session handling
- High-volume crawling support
Framework Adoption Trends
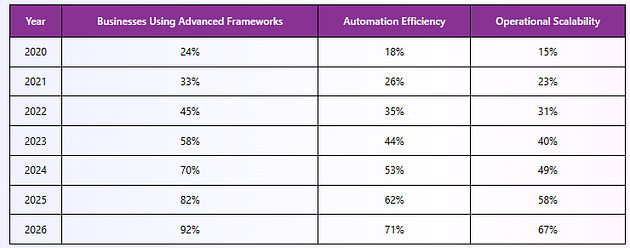
Reliable extraction frameworks help enterprises process large-scale ecommerce data while maintaining stable automation performance.
Why Distributed Strategies Reduce Detection Risks

Centralized scraping infrastructures often generate repetitive traffic signatures that are easier for anti-bot systems to identify. Distributed architectures improve operational resilience and reduce detection exposure.
Businesses increasingly adopt scalable strategies for bypassing anti-bot detection systems using cloud-based crawling infrastructure, distributed nodes, rotating proxy networks, and intelligent traffic routing systems. These architectures improve extraction success rates while supporting enterprise-scale automation workflows.
Benefits of Distributed Scraping Architectures
- Lower detection probability
- Improved request distribution
- Better infrastructure scalability
- Faster extraction workflows
- Increased operational stability
Distributed Scraping Growth Trends
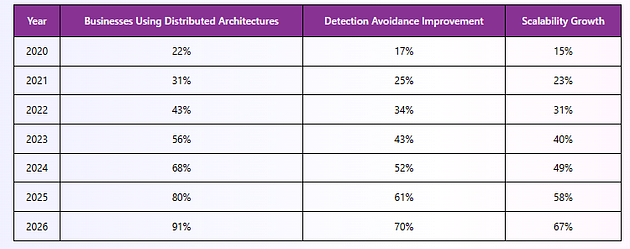
Distributed systems improve extraction continuity while supporting scalable ecommerce intelligence collection across complex online platforms.
How Intelligent Automation Improves Ecommerce Analytics

Modern businesses increasingly integrate automation technologies into ecommerce intelligence workflows to improve operational efficiency and reduce manual intervention. Intelligent automation simplifies repetitive scraping tasks while enhancing analytics scalability.
Organizations leveraging Robotic Process Automation can automate product monitoring, inventory tracking, pricing intelligence, and structured data processing workflows more efficiently. Automation frameworks improve extraction consistency while reducing operational complexity.
Benefits of Intelligent Automation
- Faster ecommerce data processing
- Reduced operational workload
- Improved extraction consistency
- Automated reporting workflows
- Better analytics scalability
Automation Adoption Statistics
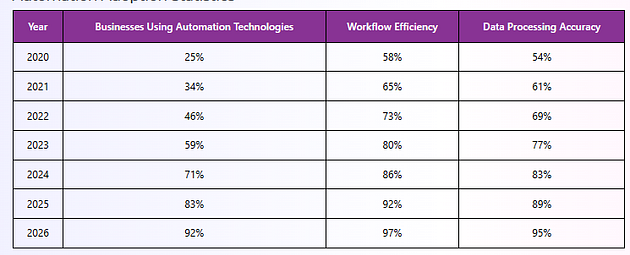
Automation technologies help businesses improve ecommerce intelligence workflows while supporting large-scale analytics operations.
Why AI Is Transforming Modern Web Scraping
Artificial intelligence is increasingly improving the adaptability and intelligence of modern scraping systems. AI-driven automation frameworks can optimize request patterns, identify extraction failures, and improve anti-bot response handling dynamically.
Businesses increasingly integrate Generative AI into ecommerce intelligence workflows to enhance automation adaptability and improve extraction reliability across dynamic web environments. AI-powered systems can support intelligent parsing, behavioral simulation, and anomaly detection in large-scale scraping operations.
Benefits of AI-Driven Scraping Systems
- Adaptive request optimization
- Intelligent extraction monitoring
- Dynamic error handling
- Automated content structuring
- Improved anti-bot adaptability
AI Adoption Trends in Web Scraping
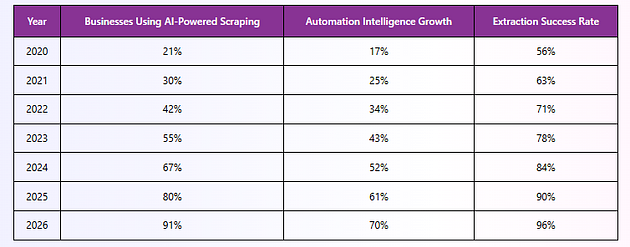
AI-driven automation frameworks improve extraction resilience while supporting smarter ecommerce intelligence operations.
Why Choose Real Data API?
Real Data API delivers enterprise-grade automation infrastructure designed for scalable ecommerce intelligence collection and advanced anti-bot management. Businesses seeking reliable Web Scraping Services can automate extraction workflows while minimizing disruptions caused by modern anti-scraping systems.
Organizations aiming to handle anti-scraping mechanisms in modern websites can leverage Real Data API for distributed crawling, intelligent request orchestration, browser automation, CAPTCHA handling, session management, and scalable extraction infrastructure.
Key Features of Real Data API
- Enterprise-grade scraping infrastructure
- Distributed proxy management systems
- Real-time extraction monitoring
- CAPTCHA and JavaScript handling support
- Intelligent automation workflows
- Scalable cloud-based architecture
- AI-powered scraping optimization
Real Data API helps businesses transform complex ecommerce extraction challenges into scalable and reliable analytics operations powered by resilient automation frameworks.
Conclusion
The increasing complexity of anti-scraping systems has transformed modern ecommerce intelligence collection into a highly technical and infrastructure-driven process. Businesses that successfully handle anti-scraping mechanisms in modern websites can maintain uninterrupted access to valuable market intelligence while improving analytics scalability and operational efficiency.
Advanced automation frameworks, distributed crawling architectures, intelligent request orchestration, and AI-powered scraping systems help organizations overcome modern anti-bot protections effectively. Real Data API provides enterprise-grade infrastructure that enables scalable, reliable, and high-performance ecommerce intelligence collection for long-term business growth.
Contact Real Data API today to build scalable ecommerce intelligence systems powered by advanced anti-bot handling technologies and enterprise-grade web automation infrastructure!
