GLM 5.2: Architecture, Benchmarks, and What It Takes to Deploy at Scale
Author : Simplismart Ai | Published On : 27 Jun 2026
Open-weight AI models are evolving rapidly, and GLM 5.2 has emerged as one of the most capable releases in this category. Developed by Z.ai, GLM 5.2 combines frontier-level reasoning with a permissive MIT license, making it an attractive option for enterprises, developers, and AI infrastructure teams.
Beyond its benchmark performance, GLM 5.2 introduces architectural improvements designed to support long-context inference and production-scale deployment. However, running a model of this size requires significant infrastructure planning. This article explores the model's architecture, benchmark results, deployment requirements, and how Simplismart simplifies production inference.
What Is GLM 5.2?
GLM 5.2 is the successor to GLM 5.1 and is built using a Mixture of Experts (MoE) architecture. Unlike traditional dense models where every parameter is active during inference, MoE activates only a subset of experts for each token. This approach delivers strong performance while improving computational efficiency.
Some of the key specifications include:
- Approximately 753 billion total parameters
- Around 40 billion active parameters per token
- Native 1 million token context window
- Maximum output length of 131,072 tokens
- Pre-trained on 28.5 trillion tokens
- Released under the MIT License, allowing unrestricted commercial use
The 1 million token context window is one of the model's biggest differentiators, enabling significantly longer reasoning, document understanding, and enterprise-scale workflows.
Architecture Improvements in GLM 5.2
GLM 5.2 introduces architectural optimizations that improve long-context inference while reducing computational overhead.
IndexShare
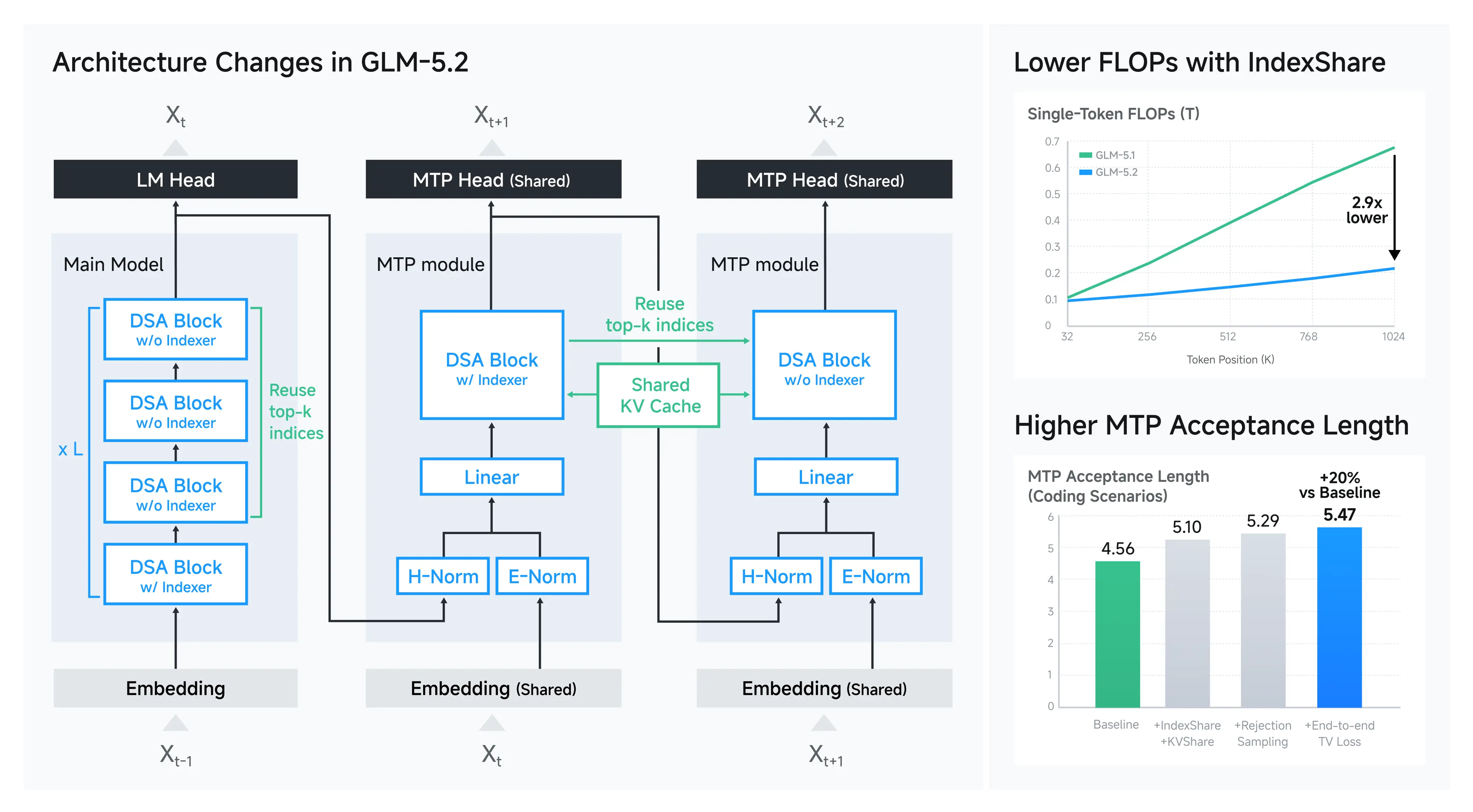
One of the major innovations is IndexShare, which reuses the same indexer across every four sparse attention layers.
According to Z.ai, this reduces per-token floating-point operations (FLOPs) by approximately 2.9× when operating at the full one-million-token context window. Lower FLOPs translate into improved inference efficiency without sacrificing capability.
Improved MTP Layer
The model also features an enhanced Multi-Token Prediction (MTP) layer that improves speculative decoding.
Z.ai reports roughly a 20% increase in acceptance length, allowing faster text generation depending on the inference stack being used.
Adjustable Thinking Effort
GLM 5.2 introduces multiple "thinking effort" levels for coding tasks.
This gives organizations flexibility to optimize for different workloads:
- Interactive coding assistants that prioritize low latency
- Batch code generation
- Large-scale code refactoring
- Enterprise software development pipelines
These improvements make GLM 5.2 practical not only for research but also for production AI applications.
GLM 5.2 Benchmark Performance
Benchmark scores are only part of the story, but they provide useful insight into model capability.
One important observation highlighted in independent evaluations is that GLM 5.2 generates approximately 43,000 output tokens per task on average. While this contributes to stronger reasoning over long horizons, it can also increase inference costs.
Artificial Analysis Intelligence Index
According to Artificial Analysis, GLM 5.2 currently ranks as the highest-performing open-weight model.
Key benchmark results include:
- Artificial Analysis Intelligence Index v4.1: Score of 51
- MiniMax M3: 44
- DeepSeek V4 Pro Max: 44
- Kimi K2.6: 43
These rankings position GLM 5.2 at the top of today's open-weight ecosystem.
GDPval-AA v2
GLM 5.2 also achieved a score of 1524 on GDPval-AA v2.
Artificial Analysis notes that this performance is competitive with proprietary frontier models, including GPT-5.5 in high-reasoning configurations.
Improvements Over GLM 5.1
Compared with its predecessor, GLM 5.2 demonstrates meaningful improvements across all eight major evaluation benchmarks, including:
- SWE-bench Pro
- Humanity's Last Exam
- TerminalBench v2.1
- NL2Repo
- Additional reasoning and coding evaluations
Overall, the model narrows the gap between open-weight and closed-source frontier AI systems.
What Does It Take to Deploy GLM 5.2?
Although only around 40 billion parameters are active during inference, the model's total parameter count creates substantial infrastructure requirements.
The biggest deployment challenges include:
- GPU memory (VRAM)
- High-bandwidth interconnects
- KV cache growth
- Multi-node coordination
- Throughput optimization
In practice, deployment complexity extends far beyond loading model weights.
Estimated Memory Requirements
The official Hugging Face repository distributes GLM 5.2 across 282 safetensor files totaling approximately 1.51 TB.
Estimated memory requirements include:
- BF16 weights: Approximately 1,506 GB
- FP8 quantized weights: Approximately 753 GB
Quantization significantly reduces memory usage while maintaining practical production performance.
KV Cache Scaling
The model's massive one-million-token context window introduces another major memory requirement: the KV cache.
Estimated KV cache usage includes:
- BF16 KV cache: Around 160 GB
- FP8 KV cache: Around 80 GB
- CUDA runtime and activation overhead: Approximately 30–60 GB
Combining model weights with KV cache results in an overall serving footprint of roughly 830–950 GB when using FP8 weights and FP8 KV cache.
In practice, this typically requires:
- At least 12 NVIDIA H100 (80 GB) GPUs, or
- Approximately 8 NVIDIA H200 (141 GB) GPUs
These estimates provide enough headroom for reliable production inference.
Practical Deployment Challenges
Deploying GLM 5.2 involves more than hardware procurement.
Organizations must also manage:
Multi-node orchestration
Large MoE models require tensor parallelism, pipeline parallelism, and high-speed interconnects to maintain acceptable latency.
Quantization strategies
Different quantization methods affect:
- Accuracy
- Latency
- Long-context quality
- Tool-use performance
Selecting the right approach requires extensive benchmarking.
Serving stack optimization
Real-world throughput depends heavily on:
- Attention implementations
- Optimized inference kernels
- Scheduler behavior
- Speculative decoding support
These infrastructure choices often influence production performance more than benchmark scores alone.
Cost management
Because GLM 5.2 may generate very large outputs for complex tasks, inference costs depend heavily on workload characteristics. Organizations must carefully balance quality, latency, and operational expenses.
Simplismart Makes Production Deployment Easier
Running a model with more than 750 billion parameters is a significant engineering challenge.
Simplismart helps organizations avoid much of this infrastructure complexity by providing managed production inference for open-weight LLMs.
Instead of building and maintaining:
- Multi-node GPU clusters
- Distributed serving pipelines
- Quantization workflows
- KV cache optimization
- Infrastructure monitoring
teams can focus on building AI applications while Simplismart manages the deployment layer.
This reduces operational overhead and accelerates enterprise adoption of large open-weight models.
Final Thoughts
GLM 5.2 represents a major milestone in open-weight language models. With its MIT license, one-million-token context window, Mixture of Experts architecture, and leading benchmark performance, it delivers capabilities that rival many proprietary frontier models.
However, its impressive capabilities come with equally demanding infrastructure requirements. From GPU memory and KV cache scaling to distributed serving and cost optimization, production deployment requires careful planning.
For organizations looking to leverage GLM 5.2 without managing complex infrastructure, platforms like Simplismart offer a practical way to deploy and scale large language models efficiently while reducing operational burden.
